Reducing the size of single or multiple PDF documents in GNU/Linux Bash and Python
Abstract: Compression of PDF documents is a useful technique to reduce the space occupied by these files and facilitate their transmission and storage. In this article, starting from a page devoted to compressing single PDFs, I present two methods for compressing multiple PDF documents. The reference page is as follows: “Linux shell script to reduce PDF file size (simple verification required to enter) and allows you to operate on single PDFs in command-line bash code in the GNU/Linux terminal. Based on the previous one, I tried to extend the procedure to operate on multiple PDFs. In the end I present a simple application in Python with graphical interface. I admit that I asked for some help from ChatGPT and Copilot.
Table of Contents:
- 1. The necessary condition.
- 2. The reference script for size reduction of individual PDFs
- 3. Derived script to operate on multiple PDFs.
- 4. Application in Python.
1. The necessary condition.
The necessary condition is that Ghostscript be installed in the operating system.
Verification is very simple, I report the verification and installation methods for three basic GNU/Linux distributions.
- Verification:
- In Arch Linux:
pacman -Q ghostscript. - In Ubuntu Linux:
dpkg -l | grep ghostscript - In Fedora Linux:
rpm -q ghostscript
- In Arch Linux:
- Installation:
- In Arch Linux:
sudo pacman -S ghostscript - In Ubuntu Linux:
sudo apt install ghostscript - In Fedora Linux:
rpm -q ghostscript
- In Arch Linux:
2. The reference script for size reduction of individual PDFs
This article is based on a solution found on the net, very useful for reducing individual PDF documents.
Here is the source, including the Copyright notices required by the free distribution license, taken from the reference page “Linux shell script to reduce PDF file size:
#!/bin/sh
# http://www.alfredklomp.com/programming/shrinkpdf
# Licensed under the 3-clause BSD license:
#
# Copyright (c) 2014-2019, Alfred Klomp
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
# 1. Redistributions of source code must retain the above copyright notice,
# this list of conditions and the following disclaimer.
# 2. Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
# 3. Neither the name of the copyright holder nor the names of its contributors
# may be used to endorse or promote products derived from this software
# without specific prior written permission.
#
#
# Modified by Vivek Gite to suit my needs
#
shrink ()
{
gs \
-q -dNOPAUSE -dBATCH -dSAFER \
-sDEVICE=pdfwrite \
-dCompatibilityLevel=1.3 \
-dPDFSETTINGS=/screen \
-dEmbedAllFonts=true \
-dSubsetFonts=true \
-dAutoRotatePages=/None \
-dColorImageDownsampleType=/Bicubic \
-dColorImageResolution=$3 \
-dGrayImageDownsampleType=/Bicubic \
-dGrayImageResolution=$3 \
-dMonoImageDownsampleType=/Subsample \
-dMonoImageResolution=$3 \
-sOutputFile="$2" \
"$1"
}
check_smaller ()
{
# If $1 and $2 are regular files, we can compare file sizes to
# see if we succeeded in shrinking. If not, we copy $1 over $2:
if [ ! -f "$1" -o ! -f "$2" ]; then
return 0;
fi
ISIZE="$(echo $(wc -c "$1") | cut -f1 -d\ )"
OSIZE="$(echo $(wc -c "$2") | cut -f1 -d\ )"
if [ "$ISIZE" -lt "$OSIZE" ]; then
echo "Input smaller than output, doing straight copy" >&2
cp "$1" "$2"
fi
}
usage ()
{
echo "Reduces PDF filesize by lossy recompressing with Ghostscript."
echo "Not guaranteed to succeed, but usually works."
echo " Usage: $1 infile [outfile] [resolution_in_dpi]"
}
IFILE="$1"
# Need an input file:
if [ -z "$IFILE" ]; then
usage "$0"
exit 1
fi
# Output filename defaults to "-" (stdout) unless given:
if [ ! -z "$2" ]; then
OFILE="$2"
else
OFILE="-"
fi
# Output resolution defaults to 72 unless given:
if [ ! -z "$3" ]; then
res="$3"
else
res="90"
fi
shrink "$IFILE" "$OFILE" "$res" || exit $?
check_smaller "$IFILE" "$OFILE"
The code should be placed in a file named as desired, e.g. shrinkpdf.sh with execution permissions (chmod +x ./shrinkpdf.sh).
2.1. Script analysis and usage.
The script defines a function called shrink that activates Ghostscript with a set of options for compressing the PDF.
Usage is very simple, just follow this pattern:
./shrinkpdf.sh input.pdf output.pdf [resolution]
The resolution used to shrink PDFs is specified by the res variable:
res="90"
This value is passed as an argument to the shrink function:
shrink "$IFILE" "$OFILE" "$res" || exit $?
Thus, the resolution used to shrink PDFs is 90 DPI, unless a different resolution is specified as the third argument when calling the script.
3. Derived script to operate on multiple PDFs.
Up to this point, however, there is nothing new about the formula found on the net.
Based on that solution, I tried to create a script to perform serial reductions of documents, that is, with a cycle that operates on a virtually infinite multiple number of documents.
In this script, derived from the previous one, a loop is used to iterate over all PDF files in the specified folder and the shrink function is applied to each of those documents.
#!/bin/bash
shrink ()
{
gs \
-q -dNOPAUSE -dBATCH -dSAFER \
-sDEVICE=pdfwrite \
-dCompatibilityLevel=1.3 \
-dPDFSETTINGS=/screen \
-dEmbedAllFonts=true \
-dSubsetFonts=true \
-dAutoRotatePages=/None \
-dColorImageDownsampleType=/Bicubic \
-dColorImageResolution=$3 \
-dGrayImageDownsampleType=/Bicubic \
-dGrayImageResolution=$3 \
-dMonoImageDownsampleType=/Subsample \
-dMonoImageResolution=$3 \
-sOutputFile="$2" \
"$1"
}
check_smaller ()
{
# If $1 and $2 are regular files, we can compare file sizes to
# see if we succeeded in shrinking. If not, we copy $1 over $2:
if [ ! -f "$1" ] || [ ! -f "$2" ]; then
return 0
fi
ISIZE="$(wc -c < "$1")"
OSIZE="$(wc -c < "$2")"
if [ "$ISIZE" -lt "$OSIZE" ]; then
echo "$1" >&2
fi
}
usage ()
{
echo "Reduces PDF filesize by lossy recompressing with Ghostscript."
echo "Not guaranteed to succeed, but usually works."
echo " Usage: $1 infile [outfile] [resolution_in_dpi]"
}
if [ $# -lt 1 ]; then
usage "$0"
exit 1
fi
INPUT_FOLDER="$1"
if [ ! -d "$INPUT_FOLDER" ]; then
echo "Error: $INPUT_FOLDER is not a directory."
exit 1
fi
# Loop through all PDF files in the directory
for FILE in "$INPUT_FOLDER"/*.pdf; do
[ -e "$FILE" ] || continue
OUTPUT_FILE="${FILE%.pdf}_shrink.pdf"
shrink "$FILE" "$OUTPUT_FILE" 90 || exit $?
check_smaller "$FILE" "$OUTPUT_FILE"
done
3.1. Using the new script.
This script accepts a folder as an argument and cycles through all the PDF files in that folder, applying the shrink function to each of them. Finally, it prints the names of the PDF files with reduced size.
To see the system at work simply proceed as follows:
- create a file, for example
multishinkpdf.sh - make it executable with
chmod +x multishrinkpdf.sh - run the file passing, as the second argument, the address of a folder containing the PDFs to be reduced.
At the end of the operation in the same folder you will find the original and reduced PDFs with the _shrink extension.
3.2. What resolution?
The resolution is, again, preset to 90 DPI, but you can pass a different value as the third argument to the shrink function.
For example, to shrink PDFs to 150 DPI, you need to modify the call to the shrink function like this:
shrink "$FILE" "$OUTPUT_FILE" 150 || exit $?
This will shrink PDFs using a resolution of 150 DPI instead of 90 DPI.
You can specify any resolution value to find the ideal balance between reduction and weight of documents.
4. Application in Python.
At this point I wondered how to create a graphic system that would perform the same function, allowing the choice of a folder containing the PDFs to be compressed and resolution in DPI.
The following is a simple implementation in Python named “PDF Shrinker”.
This is the simple application window:
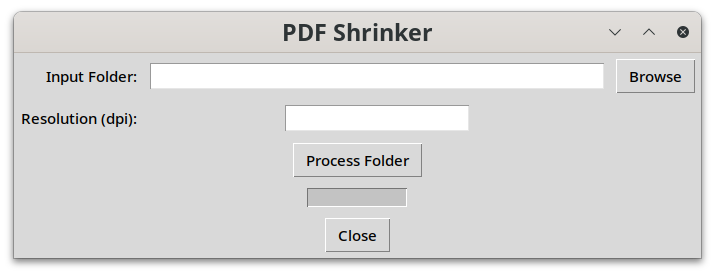
And the following is the source code:
import os
import subprocess
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter.ttk import Progressbar
def shrink(input_file, output_file, resolution, progress_var):
command = [
"gs",
"-q", "-dNOPAUSE", "-dBATCH", "-dSAFER",
"-sDEVICE=pdfwrite",
"-dCompatibilityLevel=1.3",
"-dPDFSETTINGS=/screen",
"-dEmbedAllFonts=true",
"-dSubsetFonts=true",
"-dAutoRotatePages=/None",
"-dColorImageDownsampleType=/Bicubic",
f"-dColorImageResolution={resolution}",
"-dGrayImageDownsampleType=/Bicubic",
f"-dGrayImageResolution={resolution}",
"-dMonoImageDownsampleType=/Subsample",
f"-dMonoImageResolution={resolution}",
"-sOutputFile=" + output_file,
input_file
]
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
while True:
output = process.stderr.readline().decode().strip()
if not output:
break
if output.startswith('Processing pages'):
parts = output.split(' ')
if len(parts) > 2:
current_page = int(parts[2])
progress_var.set((current_page / total_pages) * 100)
root.update_idletasks()
def check_smaller(input_file, output_file):
if not (os.path.isfile(input_file) and os.path.isfile(output_file)):
return False
isize = os.path.getsize(input_file)
osize = os.path.getsize(output_file)
return isize < osize
def browse_folder():
folder_path = filedialog.askdirectory()
if folder_path:
input_folder_entry.delete(0, tk.END)
input_folder_entry.insert(0, folder_path)
def process_folder():
input_folder = input_folder_entry.get()
if not os.path.isdir(input_folder):
messagebox.showerror("Error", f"{input_folder} is not a directory.")
return
resolution = resolution_entry.get()
try:
resolution = int(resolution)
except ValueError:
messagebox.showerror("Error", "Resolution must be an integer.")
return
total_pdf_files = sum(1 for file_name in os.listdir(input_folder) if file_name.endswith(".pdf"))
progress_var.set(0)
for index, file_name in enumerate(os.listdir(input_folder)):
if file_name.endswith(".pdf"):
input_file = os.path.join(input_folder, file_name)
output_file = os.path.join(input_folder, f"{os.path.splitext(file_name)[0]}_shrink.pdf")
shrink(input_file, output_file, resolution, progress_var)
if check_smaller(input_file, output_file):
result_listbox.insert(tk.END, output_file)
progress_var.set((index + 1) / total_pdf_files * 100)
root.update_idletasks()
def close_application():
root.destroy()
# GUI Setup
root = tk.Tk()
root.title("PDF Shrinker")
input_folder_label = tk.Label(root, text="Input Folder:")
input_folder_label.grid(row=0, column=0, padx=5, pady=5, sticky="e")
input_folder_entry = tk.Entry(root, width=50)
input_folder_entry.grid(row=0, column=1, padx=5, pady=5)
browse_button = tk.Button(root, text="Browse", command=browse_folder)
browse_button.grid(row=0, column=2, padx=5, pady=5)
resolution_label = tk.Label(root, text="Resolution (dpi):")
resolution_label.grid(row=1, column=0, padx=5, pady=5, sticky="e")
resolution_entry = tk.Entry(root)
resolution_entry.grid(row=1, column=1, padx=5, pady=5)
process_button = tk.Button(root, text="Process Folder", command=process_folder)
process_button.grid(row=2, column=0, columnspan=3, padx=5, pady=5)
progress_var = tk.DoubleVar()
progress_bar = Progressbar(root, variable=progress_var, maximum=100)
progress_bar.grid(row=3, column=0, columnspan=3, padx=5, pady=5)
close_button = tk.Button(root, text="Close", command=close_application)
close_button.grid(row=4, column=0, columnspan=3, padx=5, pady=5)
root.mainloop()
Execution requires, of course, reporting the code in a .py file and launching it with python file_name.py or python3 file_name.py.
If you find code errors please let me know.
Thank you for your attention.