Vim and Regular Expressions for removing redundant whitespace
Introduction and structure of the article
I wrote this article to practice “in situ” formula construction of Regular Expressions also called RegEx in Vim.
In particular, the goal is to “clean up” documents with excess whitespace at both the beginning and end of each line.
A basic knowledge of Vim and the Regular Expressions built into the editor is sufficient for understanding the article.
The various formulas are applied to whole documents but, since they are very normal search commands in Vim, they can be applied to individual rows or to specific ranges of rows in the context of the document.
There are three formulas illustrated and the construction is progressive with “step-by-step” analysis of the syntax of Regular Expressions.
The structure of the article is as follows: first I illustrate the creation of the formula for an end-of-line operation; then I move on to the reverse formula, i.e., for the same operation but at the beginning of the line; finally I combine the two formulas a single command that performs both operations.
Each step is preceded by a summary of the target situation and objective.
At the end of each paragraph I provide an image showing the effect of the specific formula on the text of the document.
Happy reading!
Eliminate redundant whitespace after the last word of lines.
- Reference situation: lines with numerous white spaces after the last word. May happen when copying text fragments from the Internet.
- Objective: delete by means of Vim all white spaces after the last word of each line with one composite command.
Using Regular Expressions in Vim allows you to hit the goal with a single composite command that self-replicates throughout the document.
In practice: one needs to construct the search string so as to find the reference situation to which the targeted deletion action is to be applied.
Having the purpose of selecting whitespace at the end of the line, we need to link the character that identifies, in general, whitespace (\s) with the symbol that identifies the last character of the line ($).
So the first construct could be, precisely: \s+$.
However, that construct is error because the symbol + is considered, in the syntax of Regular Expressions, to be a metacharacter that is the special character that does not identify itself but other characters.
The metacharacter in focus is a repetition operator that corresponds to a predefined sequence.
In particular, the metacharacter + identifies one or more character matches.
In practice, it does not identify only the hypothesis of no character that corresponds, instead, to other metacharacter, not the subject of the present article.
It is necessary, therefore, to undo the special nature of such a metacharacter in order to lead it back to its original graphic meaning, i.e., the mathematical addition sign.
To achieve this, it is necessary to premise the escape symbol, i.e., the character \ (also described in this article of mine), on the addition sign.
Thus the correct central sequence of the string is as follows: \s\+$.
Once the central part of the string has been resolved, it is very easy to complete the search command in Vim: we only need to activate the global search with %s\ and the desired substitution consisting of the deletion of spaces with //g (or gc) if you prefer to confirm each individual instance.
Here, then, is the complete string:
%s/\s\+$//g
The effect of the command is highlighted in the gray area:

With the possible addition of the letter c for explicit confirmation of each instance.
Personal impression: the construction of Regular Expressions starting from the middle reminds me of the construction of Latin phrases starting from the verb.
It would be interesting to explore this unusual analogy further.
Eliminate redundant whitespace at the beginning of lines
- Reference situation: lines with numerous white spaces before the first word. May happen when copying text fragments from the Internet.
- Objective: delete by means of Vim all white spaces before the first word of each line with a single composite command.
Using the same technique as above, one can easily construct a Regular Expression that performs the opposite operation: delete all whitespace present before the first word of each line.
Again, it is appropriate to start with the middle part of the formula.
If we had previously used the end-of-line symbol, it will now be necessary to use the beginning-of-line character, namely the circumflex accent: ^.
Reversing, then, the order of the factors, it will be necessary, therefore, to insert first the beginning-of-line character (^), followed by the mathematical addition sign (\+) and, lastly, by the character, already seen above, that identifies the blank spaces (\s).
Combining the three pieces gives a first composite fraction of the command: ^\+\s.
This fraction, however, is incorrect since it does not take into account that the character of white spaces is repeated only in a single instance.
With the formula sketched above, therefore, the search would end at the first whitespace in the line and leave intact all other whitespace preceding the first word in the line.
It is necessary, therefore, to introduce another repeating character, namely, the asterisk sign * which, placed immediately after the whitespace character, infinitely amplifies its scope until the first non-whitespace character is identified, which determines the end of the search sequence.
In practice The asterisk “*” compares 0, one or more of the previous characters.
We can also simplify the formula by eliminating the mathematical addition symbol since the search would stop, in any case, at the first non-white character in the line.
And here is the final formula with the additions and simplifications described above:
%s/^\s*//g
Again, the effect is highlighted in the gray area:
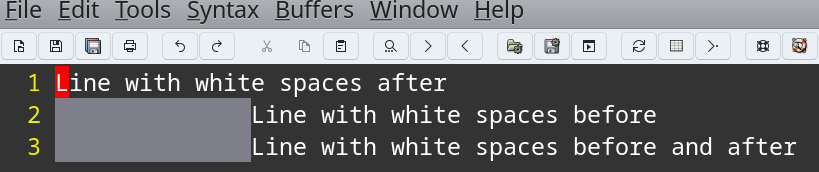
Merging the previous two formulas.
- Reference situation: rows with numerous white spaces before the first word and after the last word.
- Objective: delete by means of Vim all white spaces before the first word and after the last word of each line with a single composite command.
It is obvious that, at this point, the question occurs that it is possible to combine the two previous commands into one command.
It is possible but some additional explanation is needed.
Again, the starting point is the middle part of the construct, which must include both the first search string and the second, joined by an alternative operator of type or, that is, one that identifies both the first and the second reference situation described above.
The operator in question is the vertical bar, i.e., the | character, which must be properly preceded by the usual escape character.
But this is not enough: it is also necessary to enclose the two different fragments in round brackets, as would be the case with mathematical expressions, and to premise, at each opening and closing parenthesis, the escape character.
At the end of the process of merging the two fragments and with the appropriate modifications described above, the following composite command is obtained:
%s/\(^\s*\)\|\(\s\+$\)//g
Again you can see the effect on the gray area:

It sounds complex, but by reasoning about the individual steps that generated it as illustrated in the previous chapters, there should be no problem in clearly understanding its construction logic.
Thank you for your attention.